看到這個標題進來的,請舉手~!😀這篇來寫一下簡單幾行爬下原價屋的價目列表,差不多17行上下吧,這篇文章會從環境建置到這篇的主題,包含一些工具軟體,可以快速建置環境,這篇寫完後,以後要再寫類似的文章,環境建置都會指向這一篇文章可以不用一直重複寫,從爬取資料後到存MySQL或檔案,盡量會解釋腳本每行作用,那我們就開始。
一、網站伺服器環境建置
1.使用 Laragon 建置 Apache、PHP、MySQL 資料庫環境
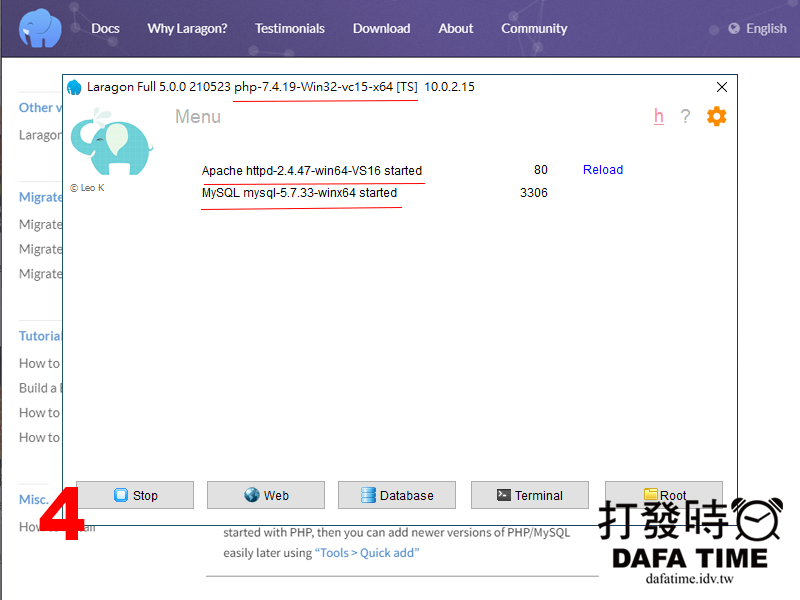
快速架站軟體 Laragon(圖1),一次就可滿足三種環境建置,還可以方便安裝或切換其牠版本,這篇會用到 MySQL 其它的一起說明,從官網下載回來檔案點兩下安裝(圖2),一直按下一步下一步就可以安裝完成,安裝完後執行 Laragon 按下面板上的 Start All 出現權限訊息都按准許確認(圖3),如果沒有出現錯誤訊息就表示,Apache、PHP、MySQL 三個都安裝成成功了(圖4),電腦已經是網站伺服器。



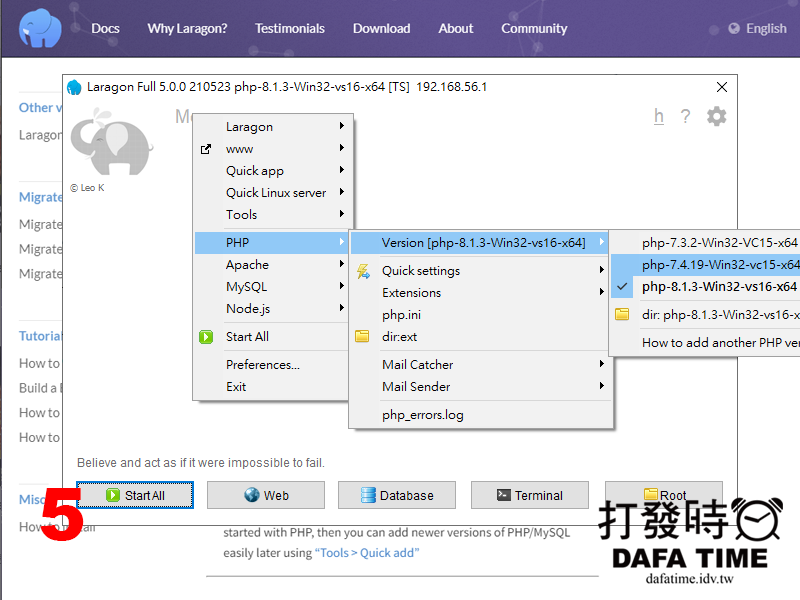
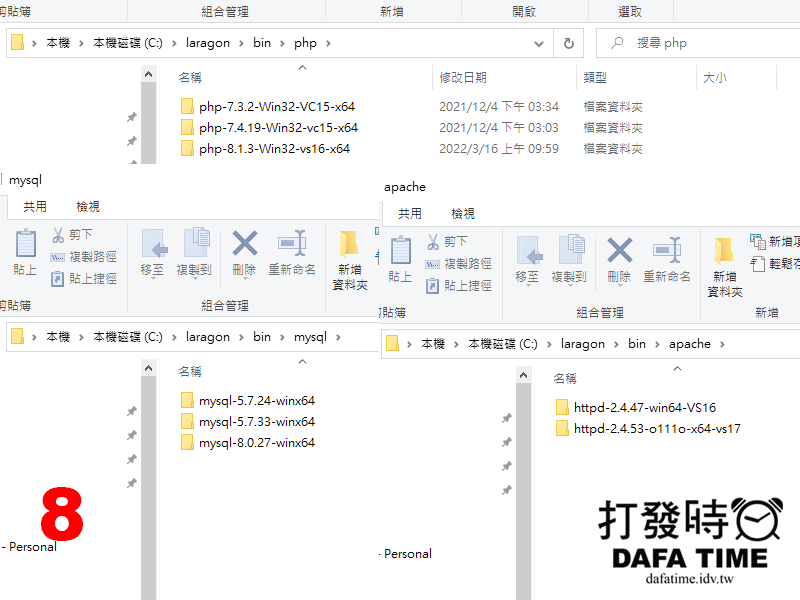
由上圖可以看到 Apache、PHP、MySQL 三個的版本,如何切換版本,其實很簡單,Menu 選單內選擇就可以切換版本(如圖5.6.7),也很簡單只要去Apacht 官網下載丟到 Laragon 目錄下的 bin\apache 資料夾裡就可以增加版本,PHP 和 MySQL 也一樣(如圖8),也不是一定要裝 MySQL 也可以安裝 MariaDB 安裝目錄也樣。


官方個版本下載位置(連結可能會因時間或官網更新造成失效ˋ)
Aapache :https://www.apachehaus.com/cgi-bin/download.plx#APACHELEVS17
PHP:https://windows.php.net/download
MySQL:https://dev.mysql.com/downloads/mysql/
MariaDB:https://mariadb.org/download/?t=mariadb&p=mariadb&r=10.6.7&os=windows&cpu=x86_64&pkg=zip&m=blendbyteu
也有可能由於版本過新 Laragon 無法正常啟動的狀況,表示 Laragon 不支援等問題。再來設定一下 MySQL 的 my.ini 檔,在上面圖6選單裡有 my.ini 選項點擊就可編輯,由於 MySQL8 版本後資料庫預設文字編碼終於不在是拉丁文了(latin1),終於~!預設便成 utf8mb4,但全域設定一樣是拉丁文(latin1),所以需要在 my.ini 內 [mysqld] 下加入兩行:
character_set_server=utf8mb4
collation_server=utf8mb4_unicode_ci存檔後按下 Laragon 面板上的 Stop 再按一次 Start All 就好,這邊底層設定目定是要,是要往後要在這個環境開發的時候比較不會出現問題,這時因該有人會問,編碼會影響到什麼,例如資料匯出匯入,產生亂碼或無法匯入,資料排序等等。
2.HeidiSQL 資料庫 GUI 軟體
再來安裝一套有 UI 的資料庫操作軟體 HeidiSQL,在終端機上打指令挺累人的,從官網下載,安裝也是下一步下一步裝完就好,雖然 Laragon 已有內建,但還是用安裝版比較好更新,使用 HeidiSQL 來看剛剛修該的地方有沒正確寫入,執行 HeidiSQL 新增一個新連線(圖9),連線名稱隨便,右邊設定可以不用動,因為是本機也沒設密碼(圖10),直接按開啟,右邊視窗頁籤”本機”下頁籤”變數” ,裡面列表如圖11位置沒有出現拉丁文(latin1)編碼,都是 utf8mb4 表示修改成功,資料庫沒有設定成 utf8mb4 編碼是無法顯示本文標題中眨眼吐舌的圖示😎。

以後只要執行 Laragon 按下 Start All 後電腦主機就是具有 Apache、PHP、MySQL 功能環境的伺服器了~!
*使用 HeidiSQL 來建立一個資料庫和資料表
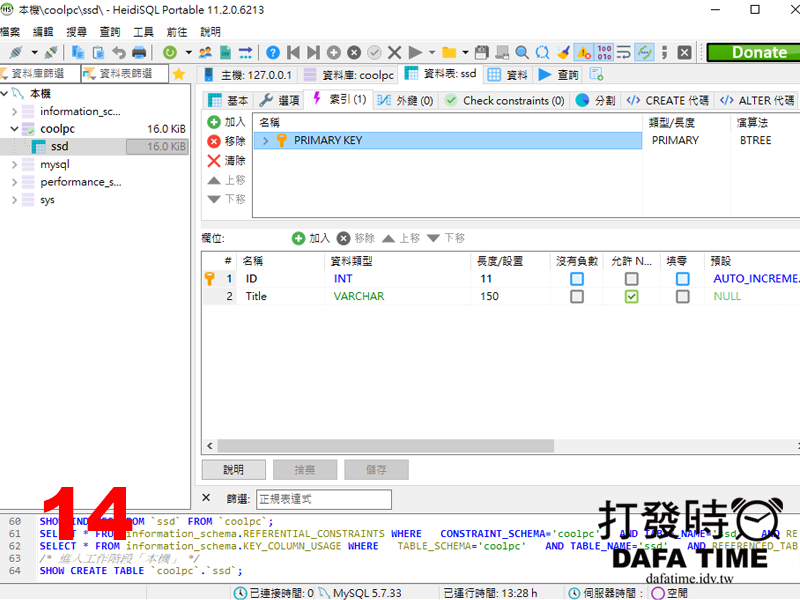
在左邊欄位滑鼠在本機上,按滑鼠右鍵點選建立新的=>資料庫(圖12),名稱我取 coolpc 按下確定(圖13),在到左邊欄位滑鼠在 coolpc 資料庫上點擊滑鼠右鍵(圖14),選單建立新的=>資料表,名稱我取 ssd 下方增加資料表欄位,ID 與 Title 兩個欄位,ID 設為主鍵(Primary key)如圖15,設定好按下儲存。


3.Python 安裝
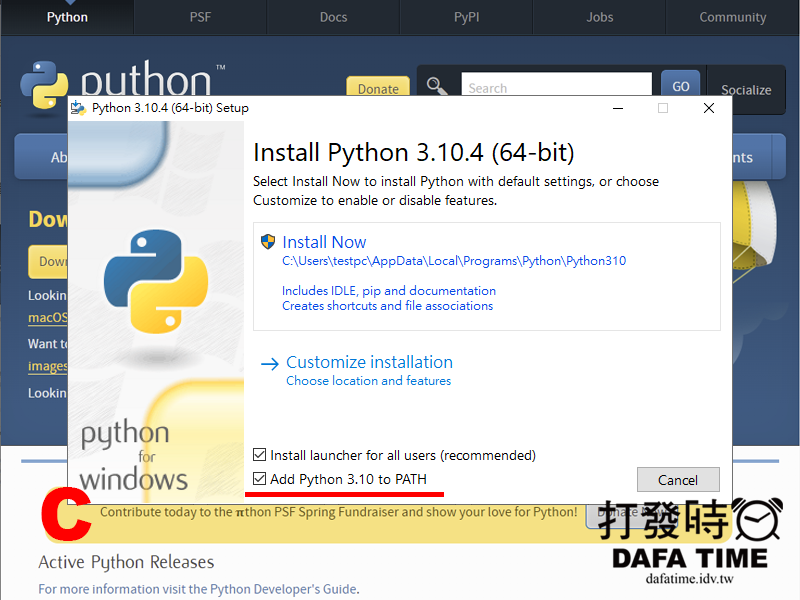
再來安裝這次的主角,Python 到官網下載最新版(圖A),點下載 Windows 版本,不知道選哪個就那個最大顆的按鈕給他按下去(圖B),執行安裝檔,安裝畫面下面最後一行記得打勾 Add Python 3.10 to PATH(圖C),再按下 Install Now 開始安裝,跑完就安裝完成。

3.Visual Studio Code (VS Code)
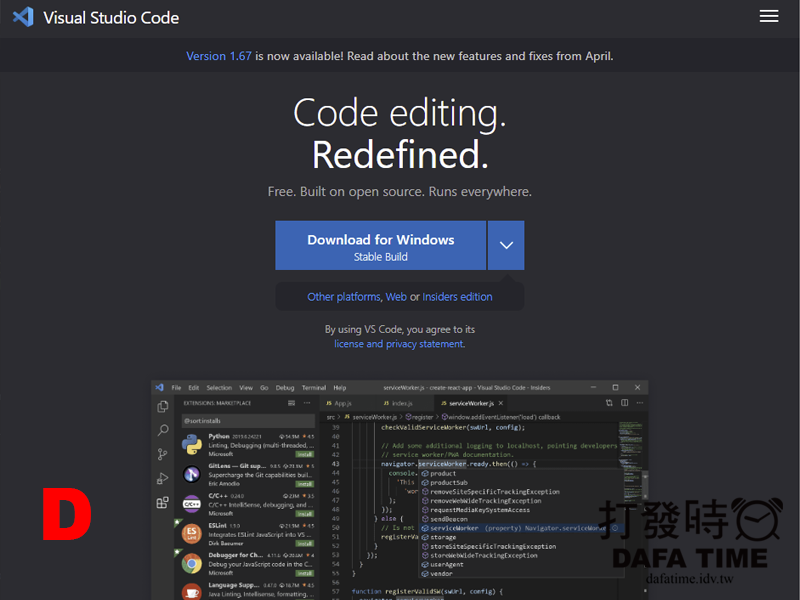
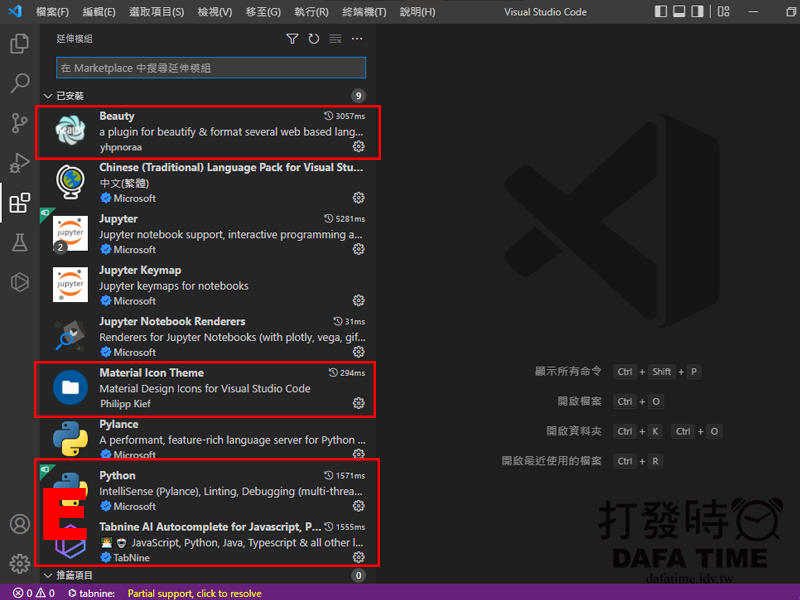
Visual Studio Code 這個編輯軟體免費又好用(圖D),到官網下載,然後安裝,安裝完後需要安裝一些延伸模組,也其它不錯用的編輯器,這篇會以Visual Studio Code 做操作,安裝完後執行,第一次執行會需要安裝一些延伸模組,如中文介面或更新,重新開啟點選左邊延伸模組圖示,安裝圖E圈起來的延伸模組,上面有搜尋框可以搜尋。
二、Python 爬取腳本
終於要到重頭戲了!開始來寫腳本,爬取原價屋網頁,開啟 VS Code 開啟一個要放腳本資料夾,腳本檔案名稱隨意,這個腳本需要再安裝兩個模組, BeautifulSoup 解析 HTML,PyMySQL 將抓到的資料存入資料庫,來安裝吧,按下快捷鍵 ctrl +` 在 VS code 下面就會出現終端機(圖1),輸入下面指令安裝組件:
//如果安裝過程出現(圖2)訊息,顯示 pip 版本過低需要更新,輸入
C:\Users\testpc\AppData\Local\Programs\Python\Python310\python.exe -m pip install --upgrade pip
//輸入完後再按 Enter
pip3 install beautifulsoup4
//輸入完後再按 Enter
pip3 install PyMySQL
//輸入完後再按 Enter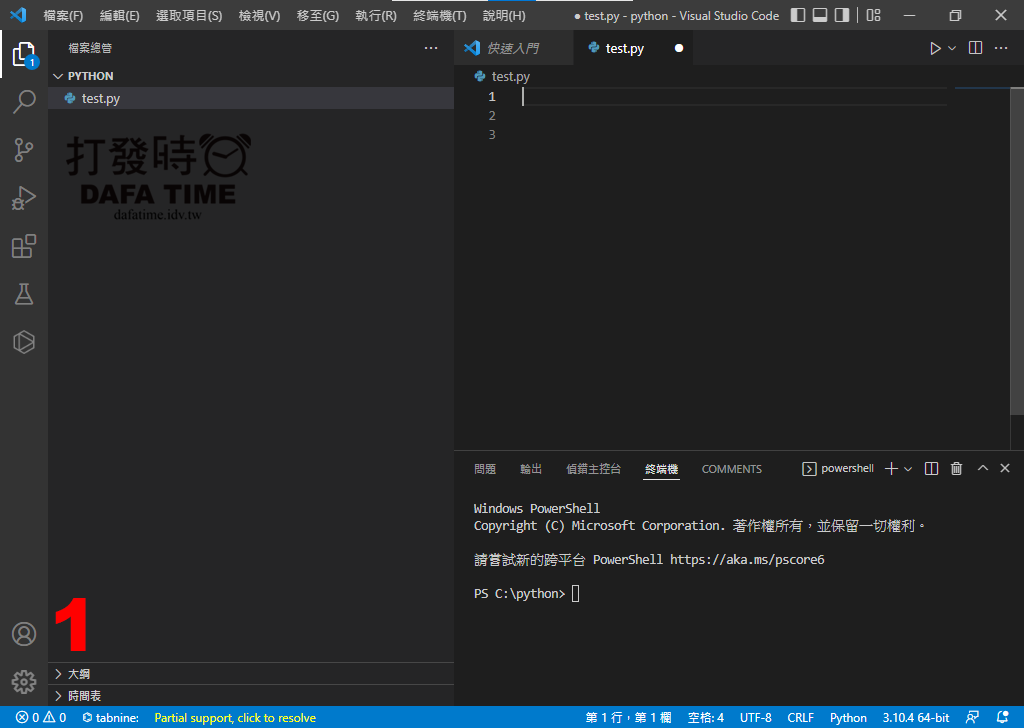

安裝完組件開始把組件載入腳本,在剛剛新建的檔案輸入:
import urllib.request
from bs4 import BeautifulSoup
import pymysql使用 urllib.request 組件撈取 HTML code:
#要爬取的網頁位置
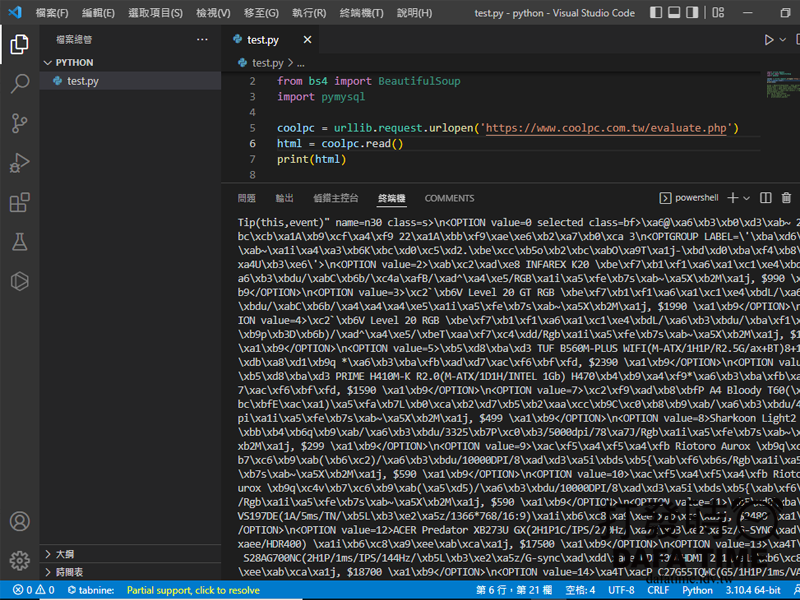
coolpc = urllib.request.urlopen('https://www.coolpc.com.tw/evaluate.php')
# read()讀取 HTML code, decode() 轉碼, 不然會變亂碼
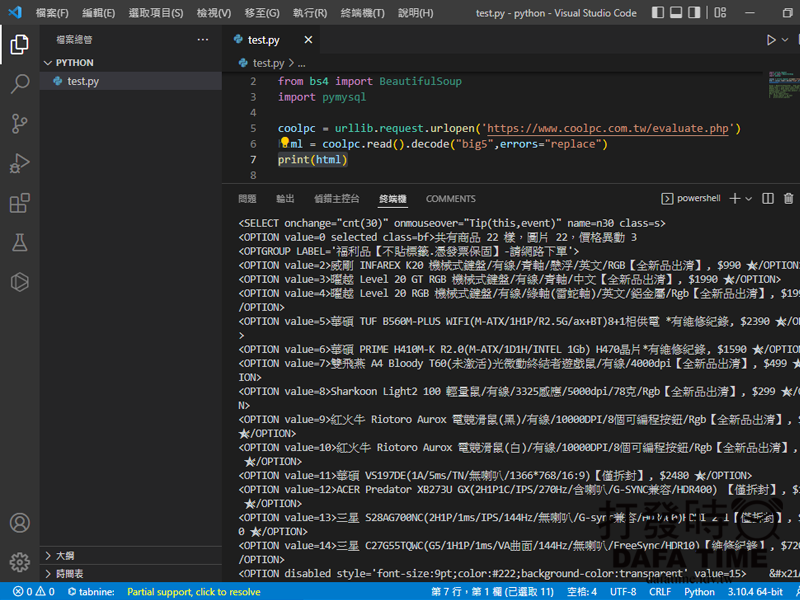
html = coolpc.read().decode("big5",errors="replace")
#列出 html 內容檢查是否有成功
print(html)在終端機下執行腳本 python test.py,可以自行試試,把 .decode(“big5″,errors=”replace”) 砍掉,看看會不會變亂碼。
使用 BeautifulSoup 組件解析 HTML code,這裡標定 HTML 位置是用 Class 如下:
#使用 BeautifulSoup 解析 html
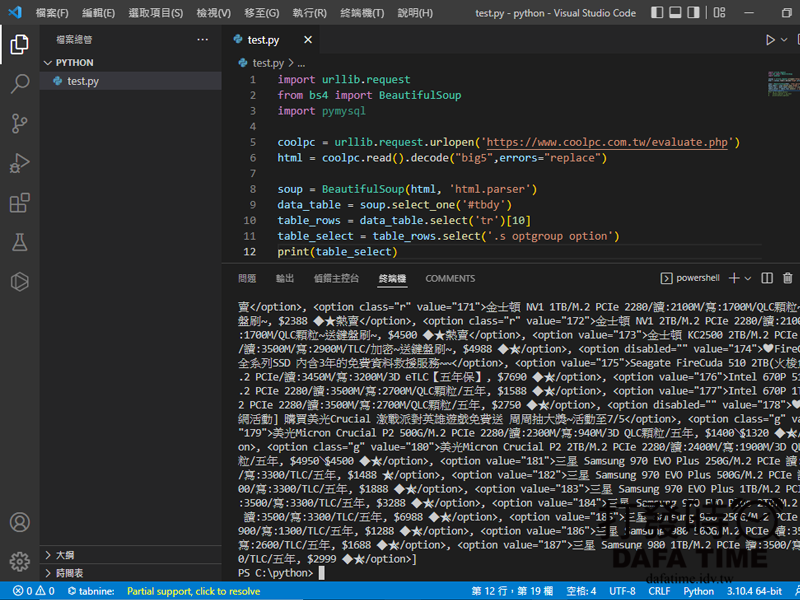
soup = BeautifulSoup(html, 'html.parser')
#選取 ID tbdy 下所有資料
data_table = soup.select_one('#tbdy')
#選取 ID tbdy 下第10個 tr 位置
table_rows = data_table.select('tr')[10]
#選取 ID tbdy 下第10個 tr 下的 class s 下的 optgroup 下的所有 option
table_select = table_rows.select('.s optgroup option')
#列出 table_select 內容檢查是否正確
print(table_select)上面的定位可以撈到 ssd 的所有列表,原價屋的 HTML 標籤有點問題,不知道是不是為了防止爬蟲,有些標籤沒有結束,如果沒有透過瀏覽器修正補上的話,在下 class 定位撈取位置無法定位到正確的位置,如 optgroup 這個標籤就沒有結束標籤,所以無法準確定位 ssd 的個別分類,到這邊就是 print 出來應該就是帶 option HTML 標籤的 ssd 資料(如圖),對於與 class 定位可以參考這篇PHP Simple HTML DOM Parser 網頁爬蟲筆記。
由於目前的資料文字以逗點分隔串在一起的,必須分段與去除 <option>標籤只要裡面裡面的文字,使用 for 回圈來拆解:
#載入 table_select 陣列, 一筆一筆讀出
for sg in table_select:
# 取 sg 文字內容,去除option標籤
select_option = sg.text
#列出 select_option 內容檢查是否正確
print(select_option)現在列出來的資料就非常乾淨,單純 option 內的文字內容,如圖。

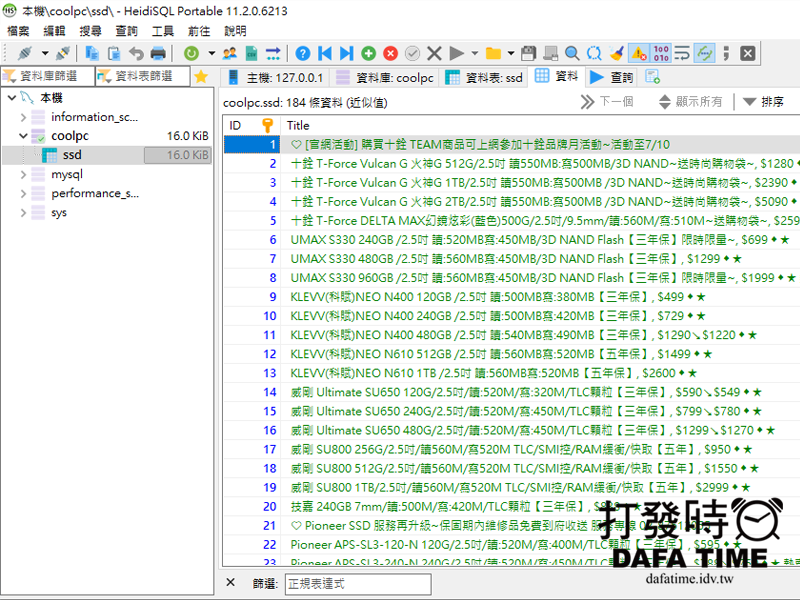
現在開始把抓到的資料存到資料庫,先與本機資料庫連線與資料庫插入語法:
#使用 pymysql 組件與資料庫連線, 這裡連線方式和PHP大同小異,主機位置、帳號、密碼、資料庫
conn = pymysql.connect(host='localhost',user='root',password='',database='coolpc')
#這個是資料庫的插入語法 INSERT INTO 資料表名稱(欄位名稱) VALUES(插入的內容), %s 等等要帶入的值
insert_sql = 'INSERT INTO ssd(title) VALUES(%s)'因為是一筆一筆寫入,所以必須寫在迴圈下面:
for sg in table_select:
select_option = sg.text
print(select_option)
#與資料庫連線
cursor = conn.cursor()
#插入資料到資料庫
cursor.execute(insert_sql, select_option)
#關閉資料庫連線
conn.commit()執行腳本後,使用 HeidiSQL 查看 ssd 資料表可以看到匯入的 ssd 列表,如圖。
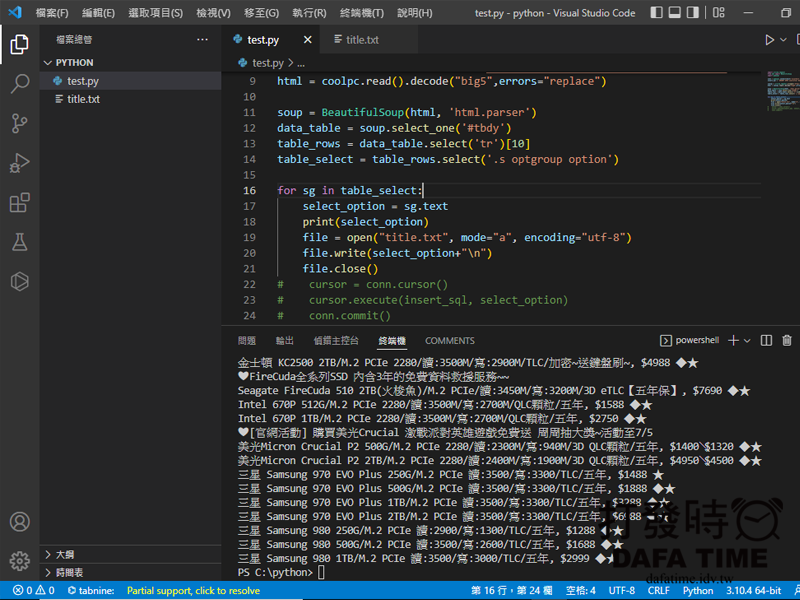
如果不想會入資料庫,也可以存成檔案,迴圈最後改成:
for sg in table_select:
select_option = sg.text
print(select_option)
#這是要設定存入檔案的名稱,mode是寫入模式,a是全部寫入的意思,後面就是寫資料的編碼utf8
file = open("title.txt", mode="a", encoding="utf-8")
#寫入的值"\n"這個是段行的意思
file.write(select_option+"\n")
#關閉檔案
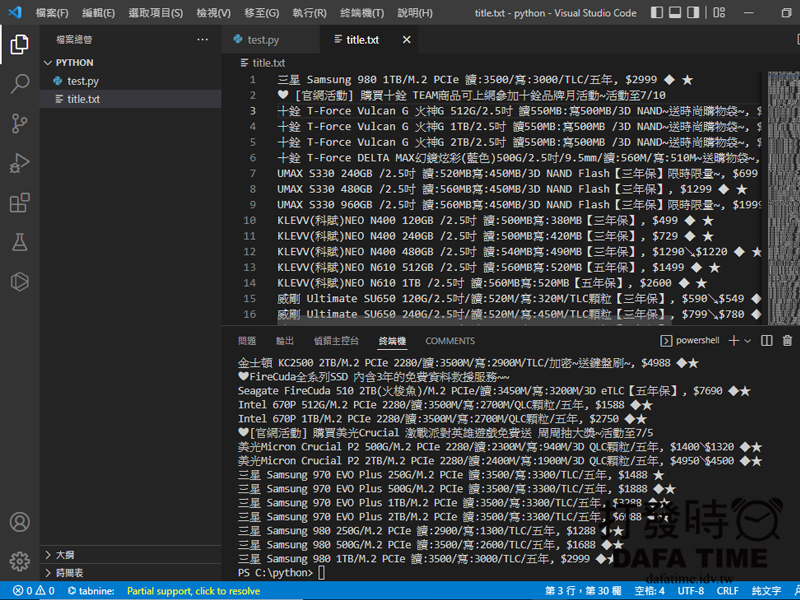
file.close()執行後就可以看到左邊檔案列表多了一個title.txt檔,如圖。
總結
使用 Python 爬取原價屋的價目表腳本就到這裡結束,HTML 內容解析定位撈取可以用 class 或是 XPach 其實看個人慣,但碰到這種少結束標籤的 XPach 有點會錯亂,這裡提供一個比較簡單的初步資料撈取,至於資料進入了資料庫,能做的事情就多了,應該有人會覺得目前的資料不太能使用,初步資料有了!資料要把它變成數據或資訊,就都不是問題,差別是你要如何使用抓下來的資料,資料一定必須經過整理才能運用,例如大家最想做的就是價格坡動統計或是商品價格查詢,網路上看到的差不多這兩類,說真的原價屋的網頁介面真的太舊了,不符合現在,假設將爬取下來的資料做一全新估價網站是可行的,資料必須整理就是了,如過有心真的有去了解HTML結構,看得懂我寫的定位,就會知道稍微修改一下就可以個別爬取如記憶體或CPU…,就這樣啦~!掰~!
*補充:完整檔案我放在Github上 https://github.com/nonelin/Python-Scraper-coolpc
*補充:這個網站 FakeShop 就是我抓下資料整理後可以運作的數據於資訊,自行享用。