
Scraper是以XPath與JQuery兩種方式來抓取網頁上的資料,這裡說明以XPath為主。
一、先認識XPath網頁HTML階層與結構概念
所看到的網頁都是以HTML碼所組成,在由瀏覽器解譯後就是我們看到的網頁,目前要抓取的mail名單HTML結構,可分為table與ul還有其他…等等,下面舉例說明。
table結構

上面表格HTML碼
<table class="staff">
<tbody>
<tr>
<th colspan="3" class="staff_cats"></th>
</tr>
<tr>
<td width="35%"><font size="-2">役職</font><br></td>
<td width="40%"><font size="-2">氏名</font></td>
<td><font size="-2">電子メールアドレス "@iae.kyoto-u.ac.jp" を補ってください。</font></td>
</tr>
<tr>
<td width="35%">所長<br></td>
<td width="40%"><a class="various" data-fancybox-type="iframe" href="/en/common/staffEJ/2017/04/post-133.html" style="opacity: 1;">岸本 泰明</a></td>
<td>y-kishimoto</td>
</tr>
<tr>
<td width="35%">副所長<br></td>
<td width="40%"><a class="various" data-fancybox-type="iframe" href="/en/common/staffEJ/2014/12/post-28.html" style="opacity: 1;">森井 孝</a></td>
<td>t-morii</td>
</tr>
<tr>
<td width="35%">所長秘書<br>
(事務補佐員)<br></td>
<td width="40%"><a class="various" data-fancybox-type="iframe" href="/en/common/staffEJ/2017/04/post-134.html">高橋 友子</a></td>
<td>t-takahashi</td>
</tr>
</tbody>
</table>上面是網頁呈現表格畫面,下面是網頁表格的HTML碼,以XPath來說我要取職稱、名子、MAIL欄位,階層路徑要如何寫,範例如下。
//table/tbody/tr/td[1] <-取得 職稱 欄位
//table/tbody/tr/td[2] <-取得 名子 欄位
//table/tbody/tr/td[3] <-取得 MAIL 欄位換個方式說,階層就像電腦的磁碟路徑一樣,如C:\Users\File\Pictures\Ashampoo,跟上面的XPath階層是不是很像,上面中括弧[1][2][3]代表示在同一層的第幾個 ,在HTML碼所顯示 tr 這一層有三個 td ,要哪一個 td 的資料就用中括弧[ ]標數字。
其它結構

HTML碼
<div class="staffsrchbox lbox">
<div class="ph"><a href="http://yagamix.st.keio.ac.jp/tprofile/personal.html?nickname=fe5ca94edecc61befdc8c586a6911cd6&test=1"><img src="http://yagamix.st.keio.ac.jp/tprofile/images/fe5ca94edecc61befdc8c586a6911cd6.jpg" alt="" title="" width="100" border="0" height="133"></a></div>
<div class="insidebox">
<p class="numb"><a href="http://yagamix.st.keio.ac.jp/tprofile/personal.html?nickname=fe5ca94edecc61befdc8c586a6911cd6">青木 義満</a></p>
<p class="info"> 学科:電子工学科<br>
専攻:総合デザイン工学専攻<br>
職名:教授<br>
キーワード:画像センシング/画像認識/コンピュータビジョ...</p>
</div>
<div class="spacer"><img src="../img/cmn/img_spacer.gif" alt="" width="1" height="1"></div>
</div>上面是網頁呈現畫面,下面是網頁的HTML碼,以XPath來說我要取職稱、名子、名子的連結,階層路徑要如何寫,範例如下。
//div/div[2]/p[1]/a <-名子
//div/div[2]/p[2]/text()[3] <-職稱
//div/div[2]/p/a/@href <-名子的連結網址上面有說明中括弧[]中的數字代表同一層的第幾個,上面階層第二行,在第二個P裡有三個 br (在網頁裡br屬斷行的意思,如同word的Shift+Enter),我們要取第三的斷行的文字,需要用的XPath語法 text()指取文字的意思,後面在加中括弧[3]就是第三個瞜!上面階層第三行的@href是指取網頁內的HTML碼的連結網址。
二、使用Scraper快速取得目標階層,在進行修改
如過有上面概念的話,在使用Scraper因該比較會知道如何下階層路徑,先說明Scraper介面功能。
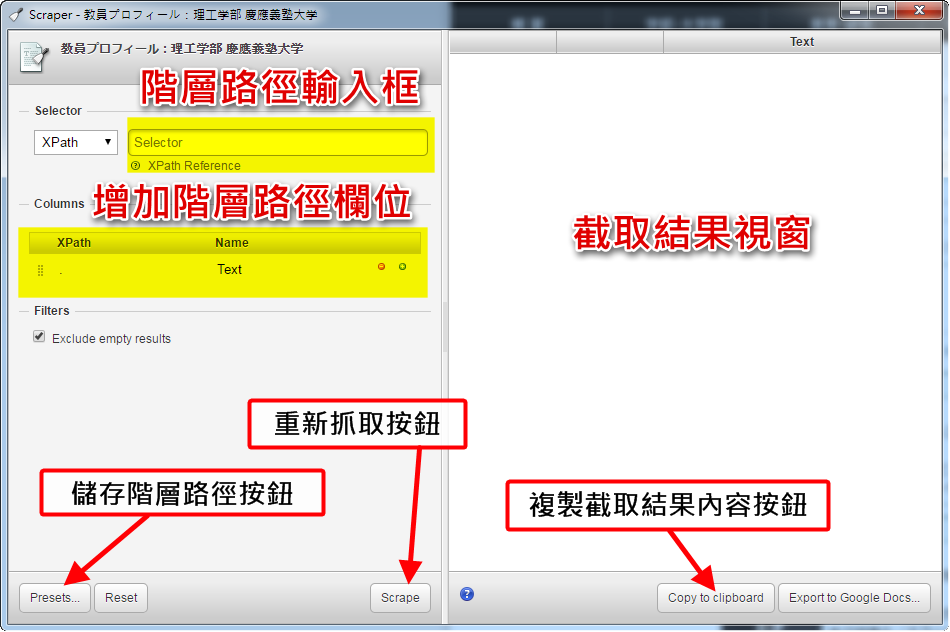
再來就以上一篇慶應義塾大学理工学部頁面為例,開始來說截取步驟。
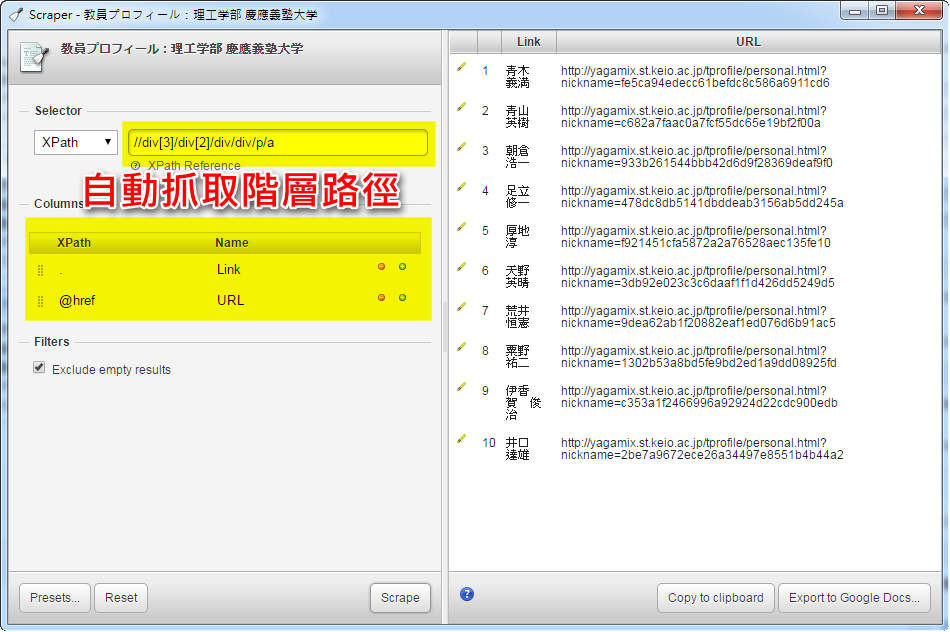
一、在慶應義塾大学理工学部頁面上教職共有288人,一個頁面有十個人,共28頁,使用Scraper截取第一頁的人名與職稱和連結。滑鼠在頁面上人名按下滑鼠右鍵->點選Scraper similar…如下圖所示.

二、會出現Scraper視窗,會自動抓取階層路徑,如下圖,欄位也自動增加一個url連結網址欄位,右邊視窗現是所抓取到的筆數和結果。
三、增加一個職稱欄位,按下綠色小按鈕增加一欄,階層路徑填入../../p[2]/text()[3],在按下Scrape重新抓取,就可以截取到職稱欄位。
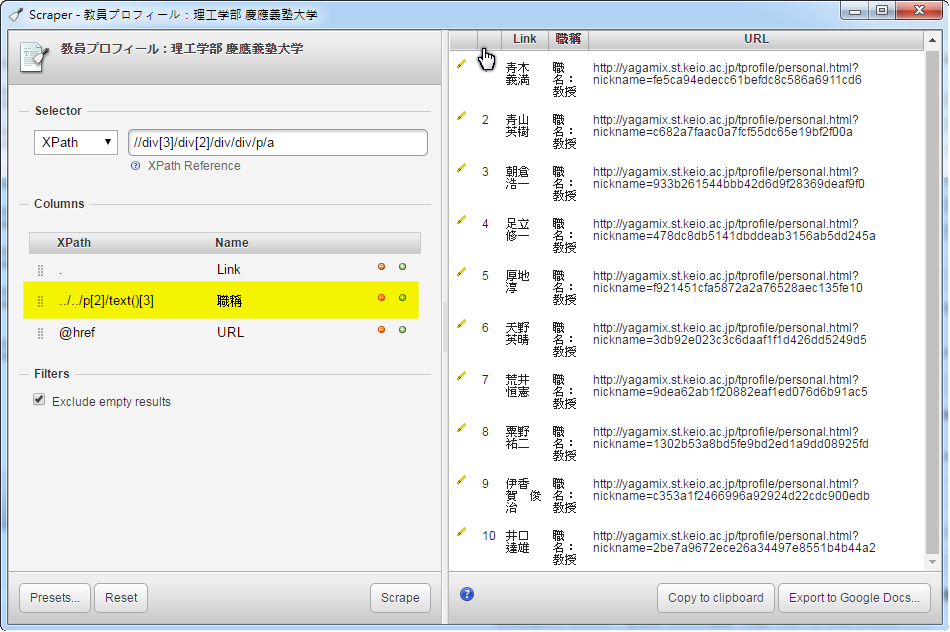
在上面HTML階層與結構概念,的其它結構已說明,已知道職稱階層路徑是div/div裡面的第二個P裡的第三個行文字(div/div/p[2]/text()[3]),Scraper自動抓取的路徑必須退兩層(//div[3]/div[2]/div/div/p/a),所以在增加職位欄位路徑輸入../../p[2]/text()[3]就可以抓到職稱。
../ <-在網頁路徑代表示是上一層的意思
../../ <-在網頁路徑代表示是上兩層的意思XPath語法參考->XPath維基
如何查詢網頁的HTML碼,查看HTML階層,善用F12與滑鼠右鍵的檢查功能



留言